|
Email / LinkedIn / Google Scholar / GitHub / Twitter / CV I am currently a Postdoctoral Researcher working jointly with Dr. Yova Kementchedjhieva and Prof. Thamar Solorio, at MBZUAI Abu Dhabi. My current research focuses on enhancing grounded generation in vision-language models (VLMs), with an emphasis on shortcut learning and reasoning-oriented VLMs. My broader interests include efficient VLMs and multi-image, structure-aware tabular VQA. Previously, I did my PhD from IIT Jodhpur as a Prime Minister’s Research Fellow, under the supervision of Dr. Anand Mishra. My doctoral thesis, Towards Effective and Scalable Vision-Language Models for Knowledge-intensive Visual Tasks, explored retrieval-augmented approaches for improving VLMs on knowledge-intensive visual reasoning tasks. |

|
News
- [May 2026] Our paper titled RA-CoA: Training-free Fashion Image Captioning via Retrieval-Augmented Chain-of-Attributes is accepted at TMLR.
- [May 2026] My first youtube live with AIRnD Labs: Link.
- [May 2026] I have successfully defended my PhD Thesis.
- [February 2026] Joined MBZUAI as a Postdoctoral Researcher.
- [December 2025] Our MPA is invited for presentation at the ACM ARCS 2026 (at IIT Hyderabad).
- [November 2025] Selected for the MBZUAI ML Winter School 2026 (60 selected from 2,400+ worldwide).
- [November 2025] Our MPA work is selected for presentation at the 'Vision India' Session in ICVGIP 2025 (at IIT Mandi).
- [November 2025] Received ACM ARCS Travel Grant (700 USD) to attend EMNLP 2025.
- [November 2025] Our paper titled PatientVLM Meets DocVLM: Pre-Consultation Dialogue Between Vision-Language Models for Efficient Diagnosis has been accepted at AAAI (Main Track) 2026.
- [October 2025] Our paper titled Mind the (Language) Gap: Towards Probing Numerical and Cross-Lingual Limits of LVLMs has been accepted at 5th MRL Workshop at EMNLP 2025.
- [August 2025] Our paper titled When Big Models Train Small Ones: Label-Free Model Parity Alignment for Efficient Visual Question Answering using Small VLMs has been accepted at EMNLP (Main) 2025.
- [August 2025] We released our latest benchmark dataset MMCricBench (10K+ downloads in a month).
- [January 2025] Got accepted into Google Deepmind Research Symposium 2025 at Google Bengaluru.
- [December 2024] Our paper titled Audiopedia: Audio QA with Knowledge has been accepted to ICASSP 2025 (Oral).
- [December 2024] Gave a hands-on tutorial to set up and efficiently train LLMs/MLLMs in CSE IITJ Winter School on GenAI.
- [November 2024] Attended EMNLP 2024 at Miami, Florida, USA, to present our TextKVQA work.
- [September 2024] Invited to present at AI for Social Good Conference at IISc Bengaluru. Presented Bharat Scene Text Dataset.
- [September 2024] Our paper titled Visual Text Matters: Improving Text-KVQA with Visual Text Entity Knowledge-aware Large Multimodal Assistant has been accepted at EMNLP (Main) 2024.
- [June 2024] Joined Adobe Research India Pvt. Ltd. as a PhD Research Intern for Summer 2024, at Bengaluru.
- [March 2024] Attended PMRF Symposium 2024, March 3-4, 2024, at IIT Indore, India.
- [February 2024] Presented RetVQA work at ACM ARCS 2024 at NISER Bhubaneswar, India.
- [November 2023] Gave a hands-on tutorial on Faster R-CNN, Seq2Seq models, Transformers (BERT, GPT, T5, ViT). [Resources]
- [October 2023] Presented RetVQA work at AI India Track of AI-ML Systems Conference 2023 in Bengaluru, India.
- [August 2023] Attended IJCAI 2023 at Macau, S.A.R, China. My travel is supported by a travel grant of 1800 USD from Microsoft.
- [April 2023] Our paper titled “Answer Mining from a Pool of Images: Towards Retrieval-Based Visual Question Answering” accepted at IJCAI 2023 (Main Track). (15% Acceptance rate). [Project page]
- [February 2023] Received third place for my work on “Retrieval-based VQA” at Prometeo (IIT Jodhpur Technical Fest).
- [December 2022] Gave a tutorial on Sequence Models during 1st Winter School on Responsible AI organized by IIT Jodhpur. [Link to Colab].
- [December 2022] Attended ICVGIP 2022 at IIT Gandhinagar, with Nakul Sharma, and presented our work on “Contrastive Multi-View Textual-Visual Encoding: Towards One Hundred Thousand-Scale One-Shot Logo Identification”.
- [November 2022] Attended AACL-IJCNLP 2022 virtually with Prajwal, and presented our work “COFAR” (NEW)
- [October 2022] Our work "Contrastive Multi-View Textual-Visual Encoding: Towards One Hundred Thousand-Scale One-Shot Logo Identification” has been accpeted at ICVGIP 2022.
- [October 2022] Our work COFAR has been accpeted at AACL-IJCNLP 2022.
- [September 2022] Received 1st prize in “Experiential Interface” track for my work on “Retrieval-based VQA” in Youth Conclave organized by INAE and SERB.
- [August 2022] Served as a reviewer for ICVGIP 2022.
- [August 2022] Our US patent “SYSTEM AND METHOD FOR INTELLIGENT RECRUITMENT MANAGEMENT” is granted. (Patent No. US 11410097 B2).
- [April 2022] Gave a tutorial on pre and post transformer-era vision-language research, VL2G Lab, Dept. of CSE, IIT Jodhpur. Lecture plan and slides can be found: [here]
- [March 2022] Received “Best presentation award” and “Constructive interaction award” in ‘Departmental Student Seminar Series’ by Department of CSE, IIT Jodhpur.
- [November 2021] Got selected as Prime Minister Research Fellow (PMRF, MoE, GoI). [Link]
- [August 2021] Got accepted into “CVIT 5th Summer School on Artificial Intelligence”.
- [July 2021] We (Dr. Mishra A., Abhirama P., Revanth P., & Tawatia K.) have received “Microsoft Academic Partnership Grant (MAPG) 2021”.
- [June 2021] Got accepted into “PRAIRIE/MIAI AI Summer School 2021 (France)” [certificate]
- [June 2021] Received “Good Teaching Assistant Recognition.” (for course on NLP) [certificate].
- [June 2021] Gave a talk on “Introduction to Machine Learning” in Summer school organised by Civil Engineering Dept., IIT Jodhpur. [Slides][Code][Video]
- [January 2021] Our patent “SYSTEM AND METHOD FOR INTELLIGENT RECRUITMENT MANAGEMENT” has been published. (Pub No. US2021019688A1).
- [November 2019] Joined Dr. Anand Mishra’s “Vision, Language and Learning Group (VL2G)”.
- [July 2019] Joined “IIT Jodhpur” as a PhD Scholar.
Research |
|
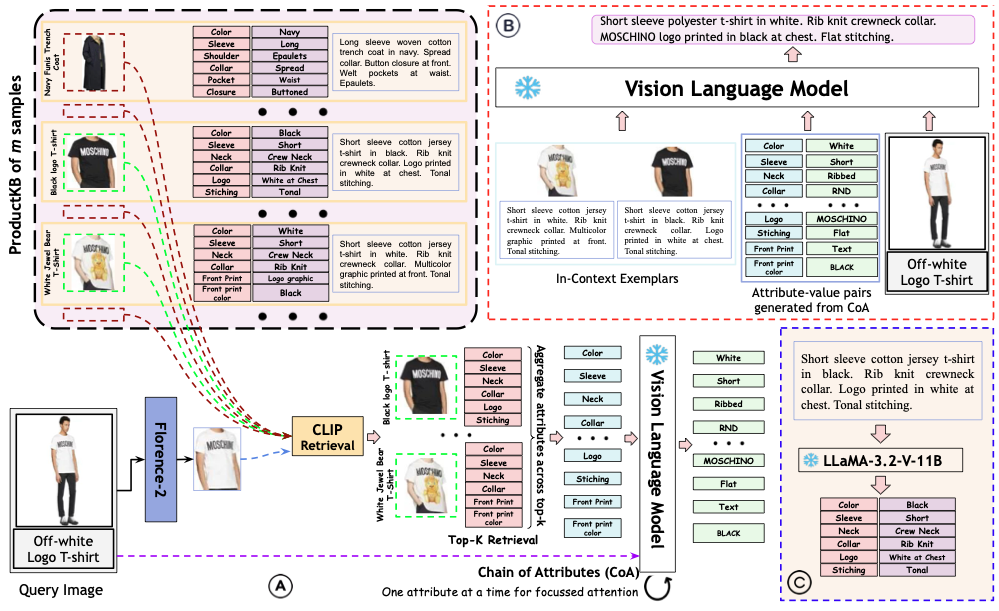
RA-CoA: Training-free Fashion Image Captioning via Retrieval-Augmented Chain-of-Attributes
Abhirama Subramanyam Penamakuri*, Shreya Shukla*, Anand Mishra. (* : equal contribution) TMLR arXiv / code (coming soon) We introduced RA-CoA (Retrieval-Augmented Chain-of-Attributes), a training-free framework that improves Fashion Image Captioning by guiding frozen VLMs toward fine-grained attribute reasoning. RA-CoA decomposes caption generation into two interpretable stages: retrieving relevant fashion attribute sets from a product knowledge base, and reasoning over those attributes to produce accurate product captions. By improving coverage of subtle details (such as necklines, closures, etc.), RA-CoA reduces hallucination in zero-shot VLM outputs, achieving an average 26.3% METEOR improvement over standard zero-shot captioning across diverse model families and prompting settings. |
|
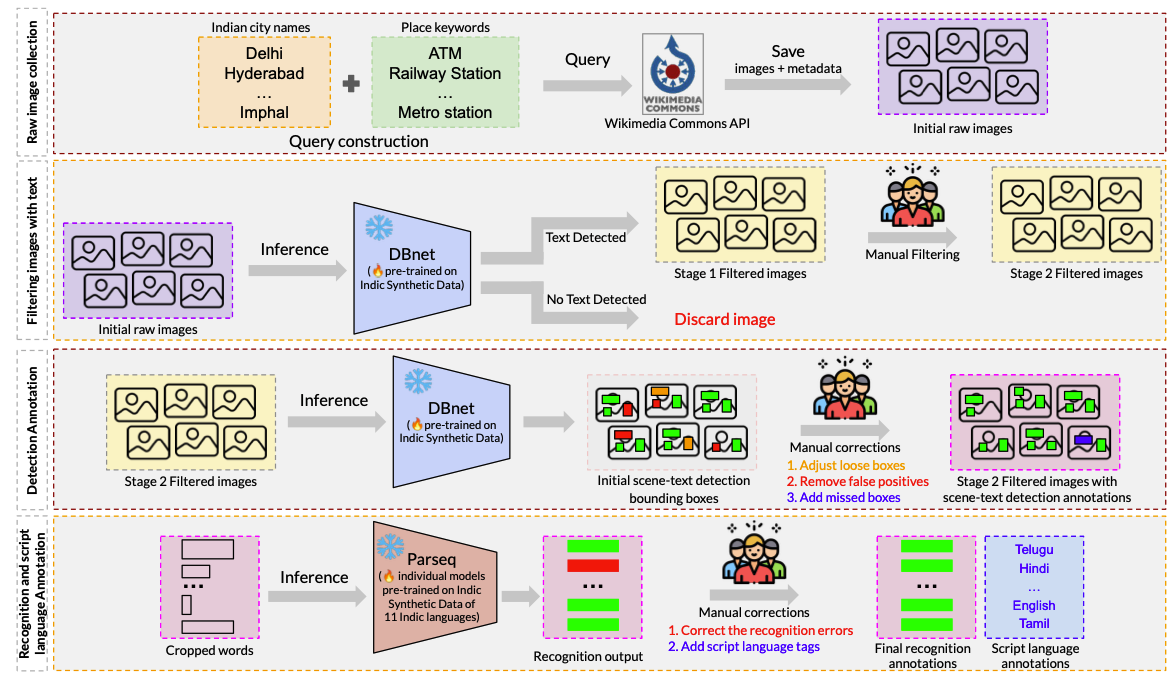
Bharat Scene Text: A Novel Comprehensive Dataset and Benchmark for Indian Language Scene Text Understanding
Anik De, Abhirama Subramanyam Penamakuri, Rajeev Yadav, Aditya Rathore, Harshiv Shah, Devesh Sharma, Sagar Agarwal, Pravin Kumar, Anand Mishra. ICDAR 2026 (Journal Track: IJDAR) arXiv / dataset / Toolkit / huggingface demo / short talk We introduced the Bharat Scene Text Dataset (BSTD), a large, real-world Indian scene-text dataset covering 13 Indian languages and English. It contains 6,582 images with 1,20,560 polygon-word annotations and 1,00,495 cropped word labels, enabling research in scene-text detection and recognition for Indian scripts. We also released IndicPhotoOCR, a toolkit for detecting and recognizing text in 11 Indian languages and English. |
|
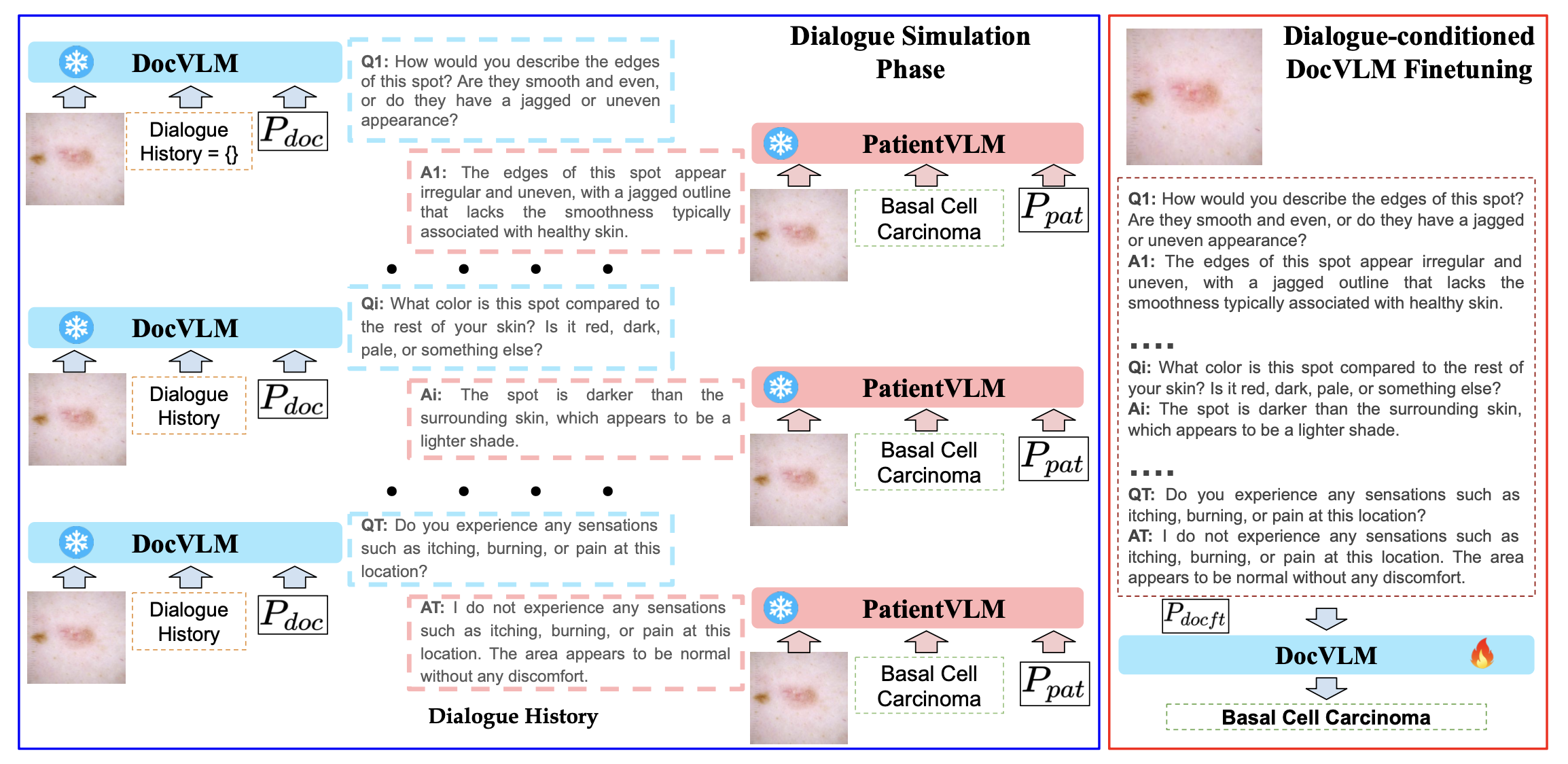
PatientVLM Meets DocVLM: Pre-Consultation Dialogue Between Vision-Language Models for Efficient Diagnosis
K Lokesh*, Abhirama Subramanyam Penamakuri*, Uday Agarwal, Apoorva Challa, Shreya K Gowda, Somesh Gupta, Anand Mishra. (* : equal contribution) AAAI (Main Track), 2026 arXiv / code / data / model We introduced the Pre-Consultation Dialogue Framework (PCDF), a scalable approach that equips Vision-Language Models with dialogue-aware, clinically realistic diagnostic reasoning. PCDF simulates multi-turn consultations by pairing a DocVLM that asks follow-up questions with a PatientVLM that provides symptom-grounded responses, producing image–dialogue–diagnosis triplets for supervision. Finetuning on this data enables DocVLM to reason contextually beyond images alone, yielding consistent accuracy and F1 improvements across four MedMNIST benchmarks. |
|
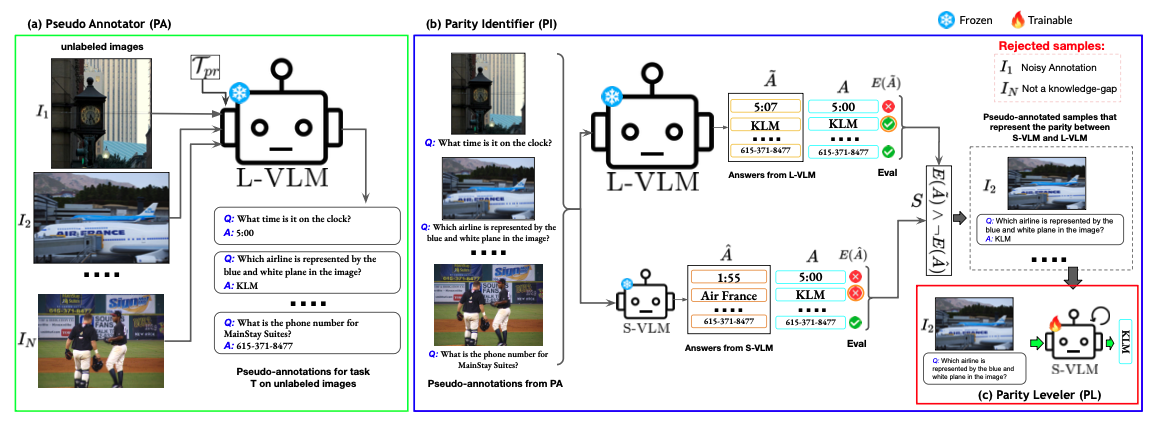
When Big Models Train Small Ones: Label-Free Model Parity Alignment for Efficient Visual Question Answering using Small VLMs
Abhirama Subramanyam Penamakuri*, Navlika Singh*, Piyush Arora*, Anand Mishra. (* : equal contribution) EMNLP (Long Main), 2025 arXiv / code We introduced the Model Parity Aligner (MPA), a label-free framework that improves Small Vision-Language Models (S-VLMs) by aligning them with larger models. Unlike traditional distillation, MPA relies only on unlabeled images and parity-based supervision to target knowledge gaps. Across four VQA benchmarks (TextVQA, ST-VQA, ChartQA, OKVQA), MPA consistently boosts S-VLM performance while retaining efficiency, and even leverages closed-source models like GPT-4o to help compact models rival or surpass much larger ones. |
|
Mind the (Language) Gap: Towards Probing Numerical and Cross-Lingual Limits of LVLMs
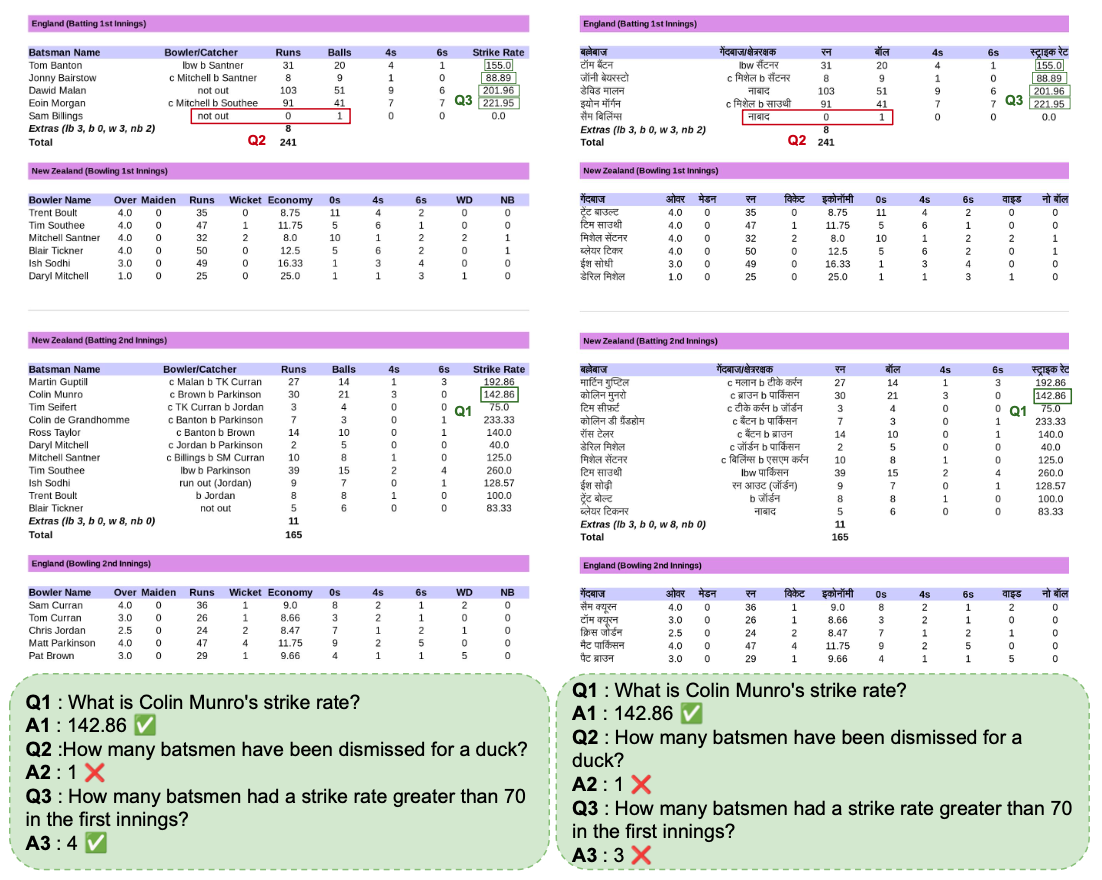
Somraj Gautam*, Abhirama Subramanyam Penamakuri*, Abhishek Bhandari, Gaurav Harit. (* : equal contribution) EMNLP MRL Workshop, 2025 arXiv / dataset Introduced MMCricBench-3K, a VQA benchmark that evaluates structure-aware, cross-lingual, multi-image, and mathematical reasoning of large vision-language models on cricket scorecards. The dataset includes 3,000 QA pairs across 1,463 English and Hindi scorecards, spanning tasks from simple retrieval to complex numerical analysis. |
|
Audiopedia: Audio QA with Knowledge
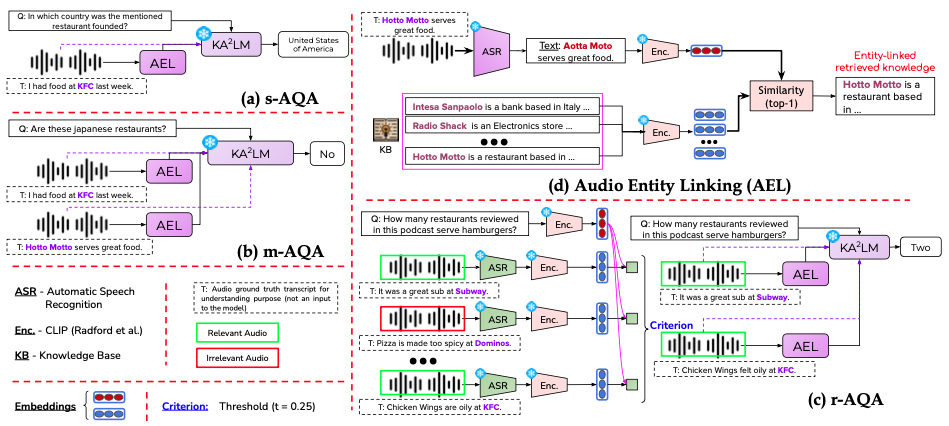
Abhirama Subramanyam Penamakuri*, Kiran Chhatre*, Akshat Jain. (*: equal contribution) ICASSP, 2025 (Oral Presentation) project page / arXiv / data / short talk Audiopedia is introduced (with 3 subtasks, s-AQA, m-AQA and r-AQA), a novel Audio QA task, requiring audio comprehension and external knowledge reasoning. Additionally, a framework that combines Audio Entity Linking (AEL) and a Knowledge-Augmented Audio Multimodal Model (KA2LM) is proposed to enhance large audio language models for knowledge-intensive tasks. |
|
Visual Text Matters: Improving Text-KVQA with Visual Text Entity Knowledge-aware Large Multimodal Assistant
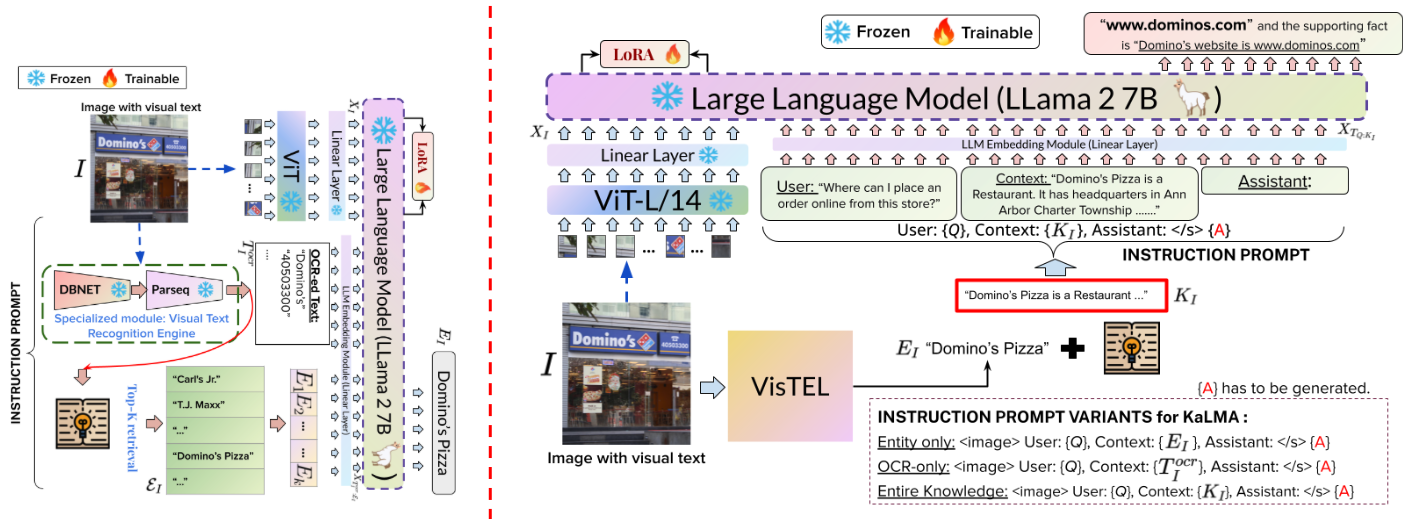
Abhirama Subramanyam Penamakuri, Anand Mishra EMNLP (Long Main) , 2024 project page / arXiv / code / poster / slides / short talk Text-KVQA is revisited with advancements in large multimodal models, introducing VisTEL, a method for visual text entity linking that leverages visual and textual cues. Additionally, KaLMA, a knowledge-aware assistant, is proposed to enhance LMMs by incorporating knowledge related to the visual text entity for improved accuracy. |
|
Answer Mining from a Pool of Images: Towards Retrieval-Based Visual Question Answering
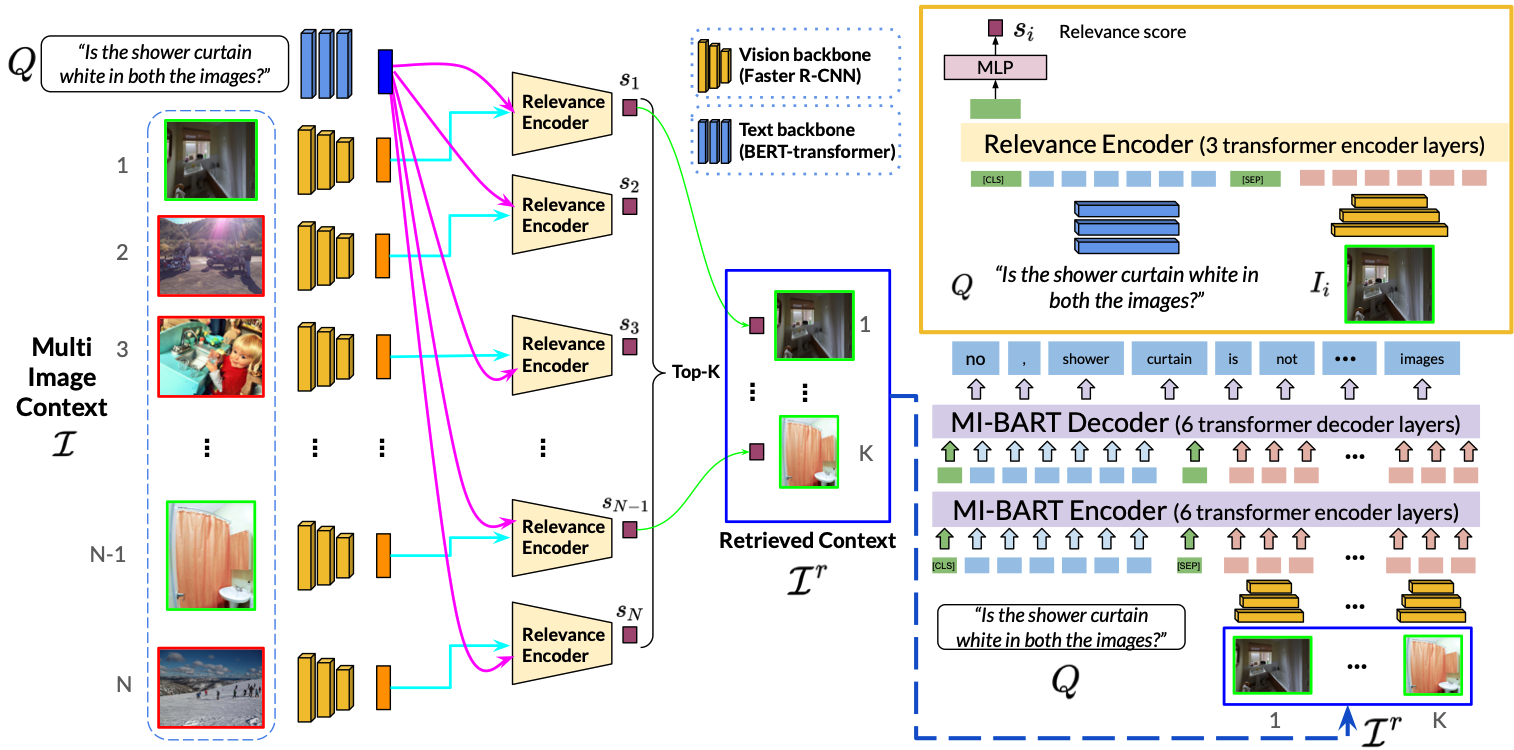
Abhirama Subramanyam Penamakuri, Manish Gupta, Mithun Das Gupta, Anand Mishra IJCAI (Main Track), 2023 (Oral Presentation) project page / arXiv / code / data / slides / short talk RetVQA is introduced as a more challenging extension of traditional VQA, where a model retrieves relevant images from a pool to answer questions. The proposed MI-BART model, along with the new RETVQA dataset, achieves significant improvements in both accuracy and fluency over existing methods. |
|
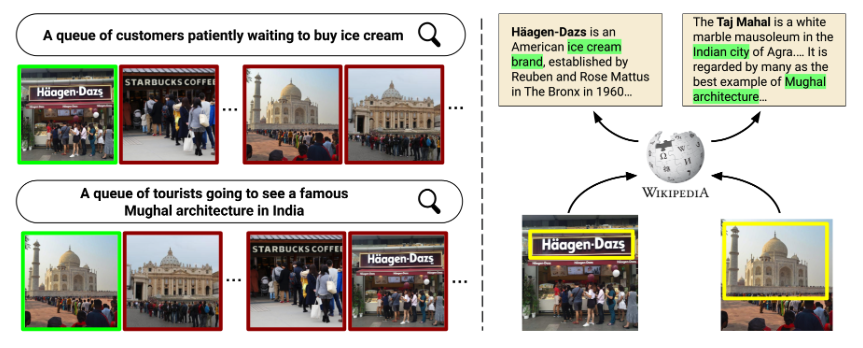
COFAR: Commonsense and Factual Reasoning in Image Search
Prajwal Gatti, Abhirama Subramanyam Penamakuri, Revant Teotia, Anand Mishra, Shubhashis Sengupta, Roshni Ramnani, AACL-IJCNLP, 2022 project page / arXiv / code / data / slides / short talk The COFAR dataset is introduced to evaluate image search involving commonsense and factual reasoning. To address this, KRAMT is proposed, integrating visual entities with encyclopedic knowledge and natural language queries for more accurate image retrieval. |
|
|
Contrastive Multi-View Textual-Visual Encoding: Towards One Hundred Thousand-Scale One-Shot Logo Identification
Nakul Sharma, Abhirama Subramanyam Penamakuri, Anand Mishra ICVGIP, 2022 project page / arXiv / paper / code / data Business logo identification in natural scenes using an open-set one-shot framework with multi-view textual-visual encoding, outperforming state-of-the-art techniques. The Wikidata Reference Logo Dataset (WiRLD) of 100,000 brand logos is introduced to study one-shot identification at scale. |
|
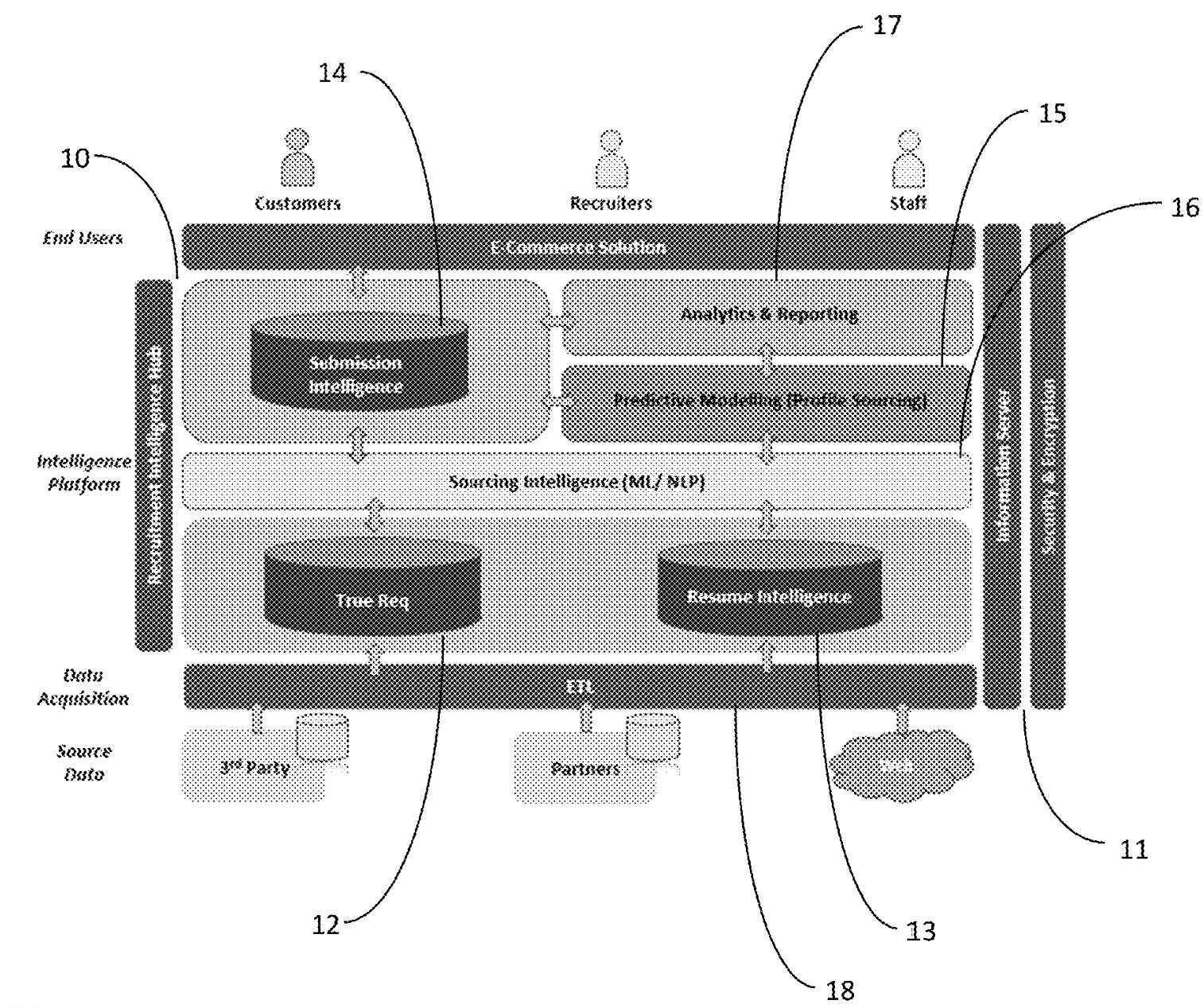
System and method for intelligent recruitement management
Subramanian Viswanathan, Janakiraman Pradeep, Inbasekaran Bharath Kumar, Roy Subhadeep, Ragavan Shankarri, S Madhuvani, Abhirama Subramanyam Penamakuri, Sirisha Kona. US Patent (Granted), 2021 The invention presents an intelligent recruitment management system that automates the recruitment process through a recruitment intelligence platform, utilizing modules for requisition parsing, resume analysis, candidate submissions, and job matching. This platform allows recruiters to track all steps of the recruitment process efficiently. |
|
Template Source: John Barron |